A few months ago, I wrote a post on building a unified backend with AWS AppSync. In the post and associated sample project, I built the backend for a conference management app (akin to what you might find at AWS re:Invent) using AWS AppSync and two data sources, Amazon DynamoDB and Amazon Elasticsearch Service. At the time of that post, AppSync also supported AWS Lambda as a data source (and has since added HTTP endpoints as well), but I was unable to think of a plausible use case at the time.
Then, I learned about Amazon Neptune, a fully-managed graph database offered by AWS that was also announced at re:Invent 2017. Graph databases are purpose-built to model relationships between entities. Whereas a relational database model of related data generally includes two tables and a foreign key, in a graph database, both the entities and the relationships between them are treated as first-class citizens. For queries that navigate these relationships, graph databases offer better performance and no need to join data together.
Graph databases can be used to solve for a number of use cases, including social networking, fraud detection, and driving directions. They are also commonly used for recommendation engines. Recommendations fit well in a conference management app, it could suggest sessions that you have not signed up for but others with similar interests (i.e. registered for similar sessions as you) already have.
In this post, I will describe how to extend the existing conference management backend to include recommendations driven by Amazon Neptune. AppSync does not yet support Neptune as a data source, so we will use Lambda as an intermediary (and finally check it off the data source list).
jkahn117/aws-appsync-session-manager-neptune
aws-appsync-session-manager-neptune - AWS AppSync Session Manager - a sample AppSync project with Amazon Neptunegithub.com
A Brief Look at Graph Database Fundamentals
One of the goals of this project was to better understand graph databases, Amazon Neptune in particular. While I now have a better appreciation for the technology, I am by no means an expert. This section will provide a brief overview of graph databases in the context of this project, but for further reading, check the References section at the end of this post.
If we were to build our same conference manager app using a relational database, the tables may look something like the following. Modeling relationships in our simple scheme would require multiple tables and foreign keys.
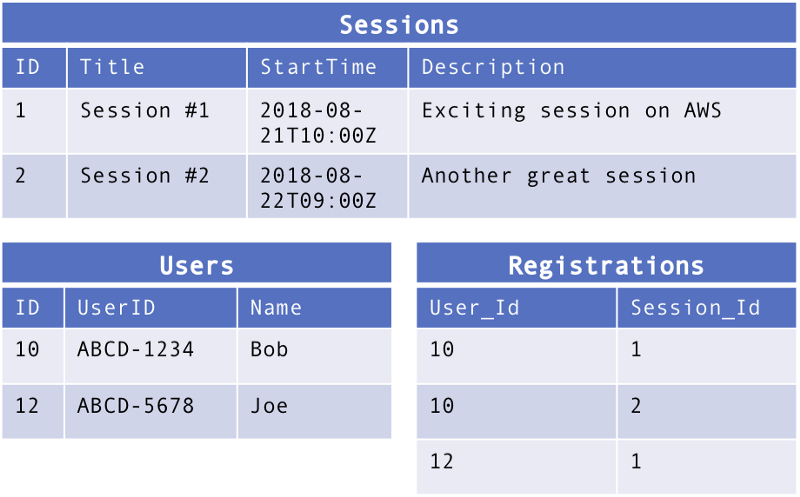
Graph databases are composed of a set of vertices, edges, and properties. Vertices are objects or entities, such as users or session. Edges define relationship(s) between vertices, in our example, users “register” for sessions. Both vertices and edges can have properties, for example a name, start time, or description. Vertices and edges also have a label, which defines their type. Edges also have direction, in and out.
Mapping our simple example above to a graph database, it is easy to understand the relationships between vertices (sessions and users) via associated edges (registrations):
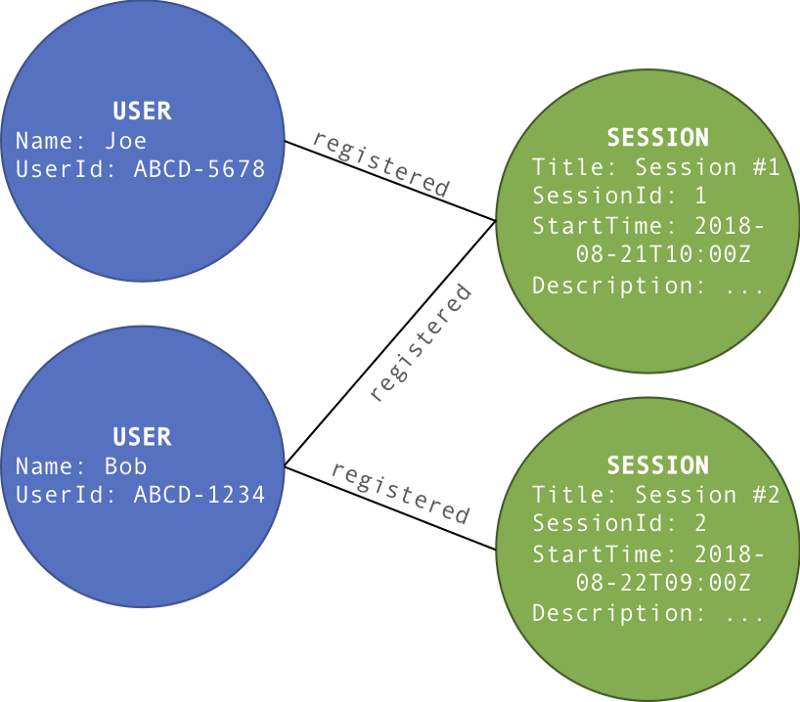
Once we have modeled and loaded data into our graph structure, we can query the graph to understand relationships between vertices. Graph database queries “traverse” edges to discover related vertices in a variety of ways (in fact, queries are known as traversals). Traversals can examine vertex and edge labels and properties.
Amazon Neptune supports two different query languages: Gremlin (Apache TinkerPop) and SPARQL (note that data is stored separately, so data loaded with one cannot be accessed by the other). For this project, I used Gremlin. Gremlin allows you to traverse your graph in a sequence of chained steps, essentially walking across the graph. Gremlin is available for a number of platforms, including Python, Java, and JavaScript.
If we wanted to find the titles of the set of Sessions the User Bob is registered for, we could write a Gremlin traversal such as:
g.V().has('User', 'Name', 'Bob')
.out('registered')
.values('Title')To go deeper on Graph Databases and Gremlin, visit the Reference links below.
Recommendations
Generating recommendations from Neptune entails first loading a current view of sessions and registrations into our graph database. The Serverless Application Model (SAM) and DynamoDB Streams make it easy to capture activity in a DynamoDB table.
In the previous phase of this project, we created two DynamoDB tables(SessionManager_sessions_table and SessionManager_user_schedule_table) to manage data related to sessions and user schedules. Using the DynamoDB Streams associated with these tables, we can invoke a Lambda function each time data changes. These functions are defined in our SAM template. The SessionStreamFunction captures new, removed, and modified session data and pushes it to our Neptune cluster. User schedule updates (registrations) are captured by the ScheduleStreamFunction and pushed to Neptune. Code for these functions can be found in GitHub.
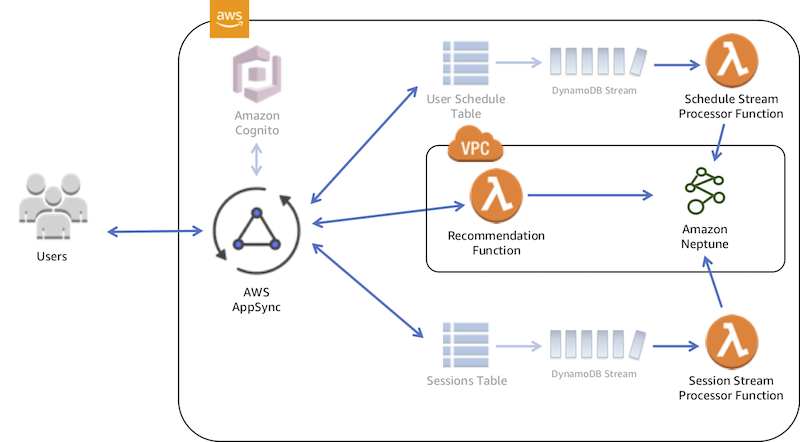
AWS Resources created in earlier work are de-emphasized.TinkerPop provides a useful recipe for generating recommendations that was implemented in the RecommendSessionFunction as follows:
g.V()
.has('User', 'userId', userId).as('user') # 1
.out('registered').aggregate('self') # 2
.in\_('registered').where(P.neq('user')) # 3
.out('registered').where(P.without('self')) # 4
.groupCount() # 5
.order(Scope.local)
.by(Column.values, Order.decr)
.next() # 6
Let’s step through each step of this traversal:
- Find a User with the property userId of a parameter value. Identify this vertex by the name user moving forward.
- Collect all vertices related to the user by outbound edges named registered and identify this group as self. These are the sessions the user is registered for.
- Then, collect all related vertices in which the collection of sessions has a registered relationship, removing the current user from those vertices. We now have a collection of User vertices that are (1) not the current user and (2) have registered for similar sessions as the current user.
- Now, find vertices the collection of Users have registered for but that the current user has not.
- Group the collection of recommended Sessions and order based on prevalence amongst the similar group.
- Execute the query.
TinkerPop documentation includes a number of other recipes for common Gremlin traversals.
Augmenting Our API
With our three Lambda functions in place, we are now (1) collecting session and registration data in Neptune and (2) ready to integrate the recommendation function with AppSync.
First, we will modify the GraphQL schema for our API to include a new query, recommendations:
type Query {
...
recommendations(userId: String): [Session]
}
Next, we add a new Lambda Data Source via CloudFormation. Here, we reference several outputs of the previous CloudFormation stack using Fn::ImportValue:
Finally, we add a new resolver for the recommendations query that will invoke the RecommendedSessionFunction, passing the expected payload. Note that our API allows us to find recommendations for either the currently logged in user or the user identified by the passed user identifier.
We can now write a GraphQL query such as the following to retrieve a set of recommended sessions for the currently logged in user:
query Recommendations {
recommendations {
SessionId
Title
}
}
The result will be a set of Sessions such as:
{
"data": {
"recommendations": [
{
"SessionId": "C516AA84-B0B1-4092-BFD5-D664D743992A",
"Title": "C5 Instances and the Evolution of Amazon EC2 Virtualization (CMP332)"
},
{
"SessionId": "A0439B4B-D359-4253-8C20-989BE39C0EE1",
"Title": "Deep Dive on the Amazon Aurora PostgreSQL-compatible Edition (DAT402)"
},
{
"SessionId": "481BE0E0-DC48-4399-8885-CF4CB7D245AC",
"Title": "Use Amazon Lex to Build a Customer Service Chatbot in Your (DEM72)"
}
]
}
}
Deploying Phase II
Details on how to deploy the complete solution using AWS CloudFormation can be found in GitHub. Remember to first deploy Phase I of the project to create AppSync, DynamoDB, and Elasticsearch resources. If you are interested in loading sample data, first deploy both phases of the project and then run the setup scripts.
I hope you have found this article useful.
jkahn117/aws-appsync-session-manager-neptune
aws-appsync-session-manager-neptune - AWS AppSync Session Manager - a sample AppSync project with Amazon Neptunegithub.com
References
- Apache TinkerPop: Getting Started
- Introduction to Graph Databases
- PRACTICAL GREMLIN: An Apache TinkerPop Tutorial
- GitHub: Apache TinkerPop