Of late, I have focused most of my development work as being “serverless-first” — it I can build it with AWS Lambda, I do. That said, there are some types of compute workloads that simply do not fit the serverless paradigm. In most cases, these tend to be long-running jobs or big data analysis that require multiple hours of ongoing work.
Solutions built on AWS Batch allow developers to build efficient, long-running compute jobs by focusing on the business logic required, while AWS manages the scheduling and provisioning of the work. I recently undertook an investigation of Batch for a customer and built a sample project that I would like to share in this post.
Brief Introduction to AWS Batch
Batch computing run jobs asynchronously and automatically across multiple compute instances. While running a single job may be trivial, running many at scale, particularly with multiple dependencies, can be more challenging. This is where using a fully managed service such as AWS Batch offers significant benefit.
AWS Batch organizes its work into four components:
- Jobs — the unit of work submitted to AWS Batch, whether it be implemented as a shell script, executable, or Docker container image.
- Job Definition — describes how your work is be executed, including the CPU and memory requirements and IAM role that provides access to other AWS services.
- Job Queues — listing of work to be completed by your Jobs. You can leverage multiple queues with different priority levels.
- Compute Environment — the compute resources that run your Jobs. Environments can be configured to be managed by AWS or on your own as well as the number of and type(s) of instances on which Jobs will run. You can also allow AWS to select the right instance type. Lastly, a scheduler owned by AWS evaluated when and where to run Jobs that have been submitted to the Job Queues.
The sample project described in the following section defines each of the above (except for the scheduler) for our simple batch job. Our focus is solely on the development of business logic (to complete the batch work) and configuration of how that work is to be completed…AWS manages the rest.
Sample Project: Image Processing
AWS Batch can support a variety of resource intensive tasks, ranging from analyzing complex financial data to screening for drug interactions. That said, our sample is rather simple … processing and tagging an image via Amazon Rekogniton (yes, this could be a Lambda function, but we’re focused on Batch today).
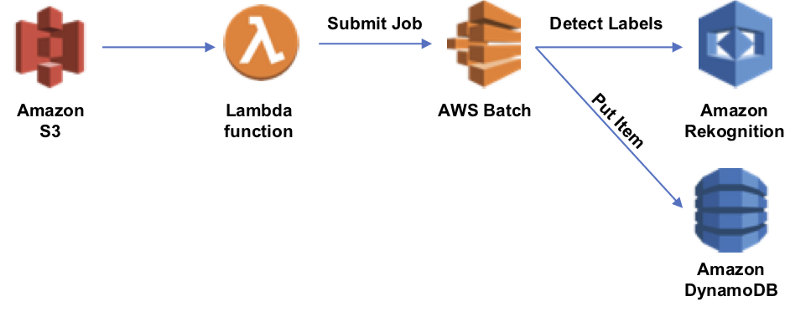
As images are put in an S3 bucket, a Lambda function is invoked, which will submit a new AWS Batch job. The job is implemented as a Docker container image, which is stored in Amazon Elastic Container Registry (ECR). Our job is a simple Ruby application that takes a set of command line arguments as input to its work. I’ve used Terraform to manage the infrastructure of this project (see template.tf)
A few comments / learnings from my exploration into AWS Batch:
- Three different IAM Roles were required: (1) Batch service role; (2) EC2 instance role for underlying instances; and (3) ECS task role (to interact with DynamoDB and Rekognition). The task role will be most familiar as it defines the AWS services the job can interact with; however, the instance role is also important (use the AmazonEC2ContainerServiceforEC2Role managed role).
- AWS Batch offers a troubleshooting guide to help with common issues. For example, I ran into “Jobs Stuck in RUNNABLE Status” due not using the aforementioned instance role.
- As part of the Job Definition, you can define both parameters and environment variables. I used parameters as values that I might override when creating the job and environment variables as values that should not be changed (e.g. AWS Region) but need to be passed to the job.
- The command defined in the Job Definition is similar to the Docker RUN command. Here, I chose to interact with my job via the command line, passing parameter values via the Job Definition command.
For further details on implementation, please see my aws-batch-image-processor repository on GitHub.